FinAI – AI Portfolio Analysis & Decision Support System
Compute-first financial analysis engine with constrained LLM interpretation
1. Problem Framing
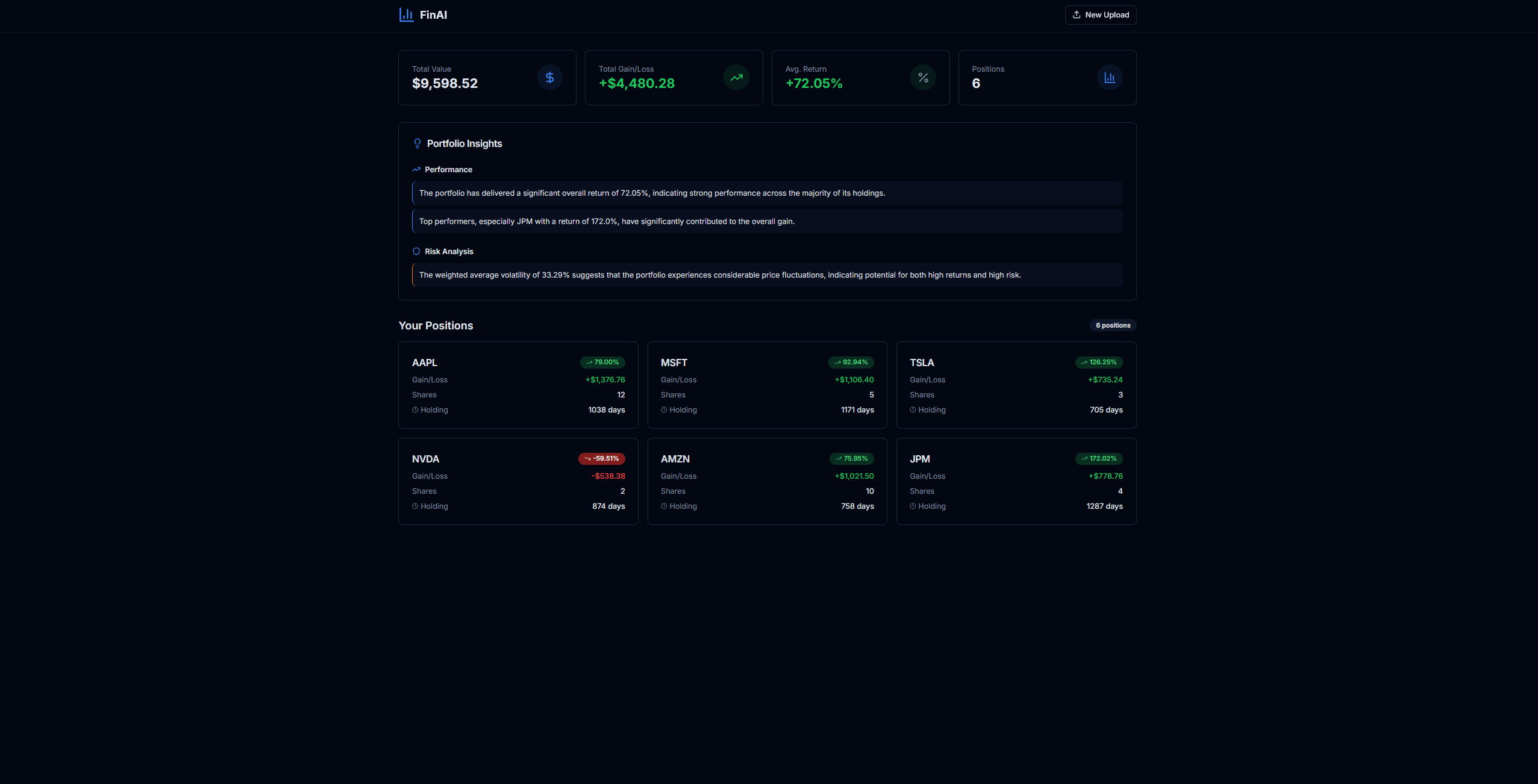
Portfolio analysis without FinAI requires manual calculation of personalized returns, risk metrics scattered across positions, and interpretation of raw data that lacks context. The problem isn't just inconvenience—it's dangerous. Financial decisions amplify small errors. A miscomputed Sharpe ratio or hallucinated correlation can lead to significant capital allocation mistakes. In financial systems, hallucinations aren't inconveniences; they're harmful.
An LLM-only solution is unacceptable. Raw data interpretation leads to hallucinated correlations, invented metrics, and overconfident summaries. The system must compute ground truth first, then interpret. Numbers are deterministic; interpretation is downstream.
2. Constraints & Explicit Non-Goals
The system is designed by removing unsafe degrees of freedom:
-
No speculative predictions or price forecasting. The system only analyzes historical data from purchase date forward.
PriceFetcherfetches historical prices; it never predicts future values. -
No free-form LLM financial advice.
InsightAgentuses structured JSON output with predefined categories (performance_insights, risk_insights, diversification_insights). The LLM cannot generate arbitrary recommendations. -
No opaque scoring or unexplained summaries. All metrics are explicit:
cumulative_return,volatility,sharpe_ratio,max_drawdown. There are no black-box scores. -
No hallucinated correlations. The LLM never sees raw price data or portfolio structure directly. It only receives computed metrics from
PositionAnalyticsAgentandPortfolioAggregator. -
No action recommendations without metric grounding. The system explains performance but does not recommend trades. Insight categories are explanatory, not prescriptive.
-
No position analytics without purchase context.
DataAgent.fetch()requirespurchase_dateandpurchase_pricefor meaningful analysis. Without these, the system returns an error rather than inventing metrics. -
No interpretation before computation. The LLM boundary is explicit:
InsightAgentreceivesportfolio_summarydictionaries with computed values, never raw DataFrames or ticker lists.
3. System Overview
The architecture enforces a compute-first boundary. The LLM interprets; it never computes.
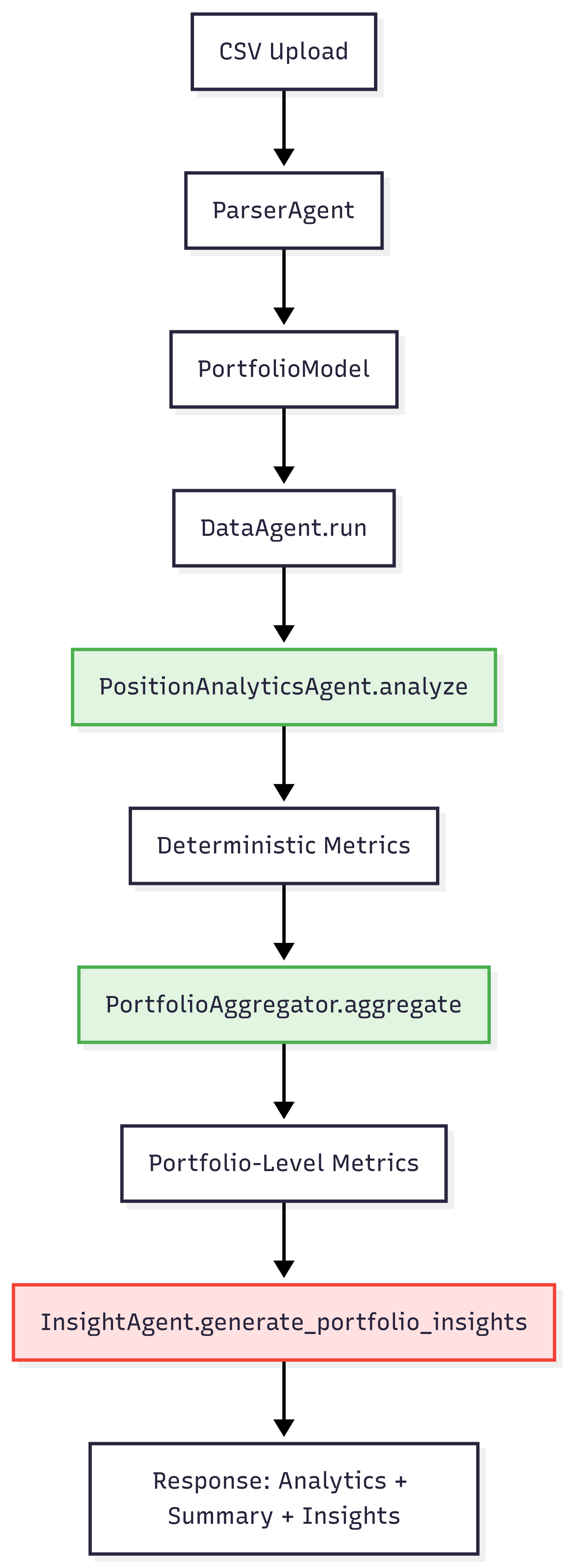
Key Boundary: The LLM only receives computed metrics, never raw price data or portfolio structure directly. This boundary is enforced at the code level: InsightAgent.generate_portfolio_insights() accepts portfolio_summary: Dict[str, Any] and analytics: Dict[str, Dict[str, Any]]—structured dictionaries of computed values, not DataFrames or raw API responses.
The flow is orchestrated in backend/app/routers/analyze.py: positions are analyzed, aggregated, then interpreted. Each layer is isolated.
4. Core Design Decisions
4.1 Deterministic Metrics Before Interpretation
Decision: All metrics are computed by PositionAnalyticsAgent.analyze() before InsightAgent is called.
Rationale: Numbers are ground truth. Interpretation is downstream. The LLM cannot hallucinate metrics or invent correlations if it never sees raw data.
Risk Mitigated: LLM hallucinations are constrained to interpretation of actual computed values. If cumulative_return is 0.15, the LLM can comment on a 15% return, but it cannot invent a different return value.
Implementation: PositionAnalyticsAgent computes cumulative_return, absolute_gain, holding_days, volatility, sharpe_ratio, and max_drawdown from historical price data and purchase context. These values are returned as a dictionary. Only then does InsightAgent receive this dictionary and generate insights.
Code Reference: backend/app/analytics/position_analytics_agent.py:42-123
4.2 Portfolio-Level Aggregation
Decision: PortfolioAggregator computes weighted averages, worst drawdown, and top/underperformers before portfolio-level insights are generated.
Rationale: Individual position commentary is misleading. A single position with 50% return doesn't mean the portfolio is performing well. Concentration and correlation matter more than individual returns.
Risk Mitigated: Prevents over-weighting single positions in portfolio analysis. The system aggregates first, then interprets at the portfolio level.
Implementation: aggregate_portfolio() computes:
- Weighted average return (by cost basis)
- Weighted average volatility
- Weighted average Sharpe ratio
- Worst drawdown across all positions
- Top and underperformers
These aggregated metrics are passed to InsightAgent.generate_portfolio_insights(), which receives portfolio-level context, not individual position details.
Code Reference: backend/app/services/portfolio_aggregator.py:9-126
4.3 Metric-Bound Summarization
Decision: InsightAgent.generate_portfolio_insights() receives portfolio_summary dict with computed values. The LLM prompt includes actual numbers, not descriptions.
Rationale: The LLM is forced to reference computed values. It cannot invent metrics because the prompt contains the actual calculations.
Risk Mitigated: All insights are traceable to actual calculations. If the prompt says "Weighted Average Return: 12.5%", the LLM must reference that 12.5% value, not invent a different number.
Implementation: The prompt template in InsightAgent.generate_portfolio_insights() includes:
Weighted Average Return: {weighted_avg_return * 100:.2f}%
Weighted Average Volatility: {weighted_avg_volatility * 100:.2f}%
Worst Drawdown: {f"{worst_drawdown * 100:.2f}%" if worst_drawdown else 'N/A'}
These are f-string interpolations of actual computed values from portfolio_summary. The LLM sees numbers, not placeholders.
Code Reference: backend/app/agents/insight_agent.py:124-152
4.4 Separation of Insight vs Action
Decision: Insight categories are "performance_insights", "risk_insights", "diversification_insights", and "recommendations" (explanatory, not prescriptive).
Rationale: FinAI explains but does not "recommend trades." The system provides context for decision-making, not commands.
Risk Mitigated: User maintains decision authority. The system provides context, not commands. Even the "recommendations" category is constrained to portfolio improvement suggestions, not specific trade instructions.
Implementation: The JSON schema in the LLM prompt specifies these categories. The LLM cannot generate arbitrary advice outside these bounds. The response is parsed and validated as JSON.
Code Reference: backend/app/agents/insight_agent.py:139-150
4.5 Explicit Tradeoff: Reduced Expressiveness for Predictability
FinAI intentionally sacrifices conversational flexibility in exchange for grounded, auditable outputs. By constraining the LLM to metric-bound summaries and predefined insight categories, the system limits expressiveness but ensures that every insight can be traced back to computed values.
This tradeoff prioritizes correctness and trust over narrative richness, which is appropriate for financial decision support systems.
5. Failure Modes & Safeguards
5.1 Sparse or Noisy Portfolio Data
Detection: Try-catch blocks in DataAgent.fetch() and PositionAnalyticsAgent.analyze() catch exceptions during data fetching or computation.
System Response: DataAgent.run() continues processing other items if one fails. Failed positions return {"error": str(e)} in the analytics dictionary. PortfolioAggregator.aggregate() skips positions with errors when computing portfolio-level metrics.
User-Visible: The frontend receives partial results. Some positions may have errors, but the portfolio analysis continues. Errors are included in the response, not hidden.
Code Reference: backend/app/agents/data_agent.py:46-52, backend/app/services/portfolio_aggregator.py:50-52
5.2 Missing Purchase Date/Price
Detection: DataAgent.fetch() validates that purchase_date exists before calling PositionAnalyticsAgent.analyze().
System Response: Returns {"error": "purchase_date is required for position analytics"} immediately, without attempting computation.
User-Visible: Error message in API response. The system fails fast rather than computing meaningless metrics.
Code Reference: backend/app/agents/data_agent.py:28-29
5.3 LLM Over-Generalization
Detection: InsightAgent uses structured JSON output with predefined categories. JSON parsing includes try-catch with fallback to empty arrays.
System Response: If JSON parsing fails or the LLM returns invalid structure, the system returns empty insight arrays plus an error message. Analytics are still available even if insights fail.
User-Visible: Insights may be empty, but position analytics and portfolio summary remain intact. The system degrades gracefully.
Code Reference: backend/app/agents/insight_agent.py:154-170
5.4 Over-Concentration Misinterpretation
Current State: Portfolio aggregator computes weighted averages but doesn't explicitly warn about concentration risk (e.g., single position > 40% of portfolio).
Gap: This is a known limitation. The system aggregates correctly but doesn't flag concentration as a risk factor.
Future Improvement: Add explicit concentration warnings in portfolio aggregation (see "What I'd Improve Next").
5.5 False Confidence from Small Sample Sizes
Detection: PositionAnalyticsAgent checks for empty data, division by zero, and insufficient history before computing metrics.
System Response: Returns None for metrics that cannot be computed. For example, Sharpe ratio requires sufficient returns history; if daily_returns.std() == 0 or history is too short, sharpe_ratio is None.
User-Visible: Metrics show as None or N/A in responses. The system prefers "insufficient data" over overconfident output.
Code Reference: backend/app/analytics/position_analytics_agent.py:98-103
6. Outcomes & Learnings
Predictability: The system consistently returns structured data, even when metrics are missing. A position with insufficient history returns None for sharpe_ratio, not a made-up value.
User Trust: Error handling ensures partial failures don't break entire analysis. If one position fails, others continue processing. The portfolio summary aggregates successfully even if some positions have errors.
System Behavior: The system prefers "insufficient data" (None values) over overconfident output. This is intentional: better to say "I don't know" than to invent a metric.
Key Pattern: Error handling uses try-except with graceful degradation. Missing data returns None instead of inventing values. Portfolio aggregation continues even if some positions fail.
7. What I'd Improve Next
-
Explicit concentration warnings: Add concentration risk detection in
PortfolioAggregator. Flag when a single position exceeds a threshold (e.g., 40% of portfolio value) and include this in portfolio insights. -
Uncertainty quantification: Explicitly flag metrics computed from small sample sizes. If a position has < 30 days of history, add a warning that volatility and Sharpe ratio may be unreliable.
-
Scenario analysis: Stress test aggregation logic with synthetic portfolios. Validate that weighted averages behave correctly under edge cases (e.g., all positions negative returns, extreme concentration).
-
Tighter uncertainty bounds: Add confidence intervals for metrics like Sharpe ratio. A Sharpe of 1.5 computed from 20 days of data is less reliable than one computed from 2 years.
-
Data quality scoring: Flag positions with incomplete purchase history or suspicious data (e.g., purchase_price that doesn't match historical prices, dates in the future). Add a data quality score to each position's analytics.
Deployment & Availability
FinAI is intentionally not deployed or open-sourced.
The system was built to explore design tradeoffs in financial AI under correctness and safety constraints, not to operate as a public-facing product. Deployment would introduce regulatory, data privacy, and misuse considerations that fall outside the scope of this project's goals.
The focus of this work is system design, risk containment, and decision intelligence — not distribution.
Final Self-Check: If this system gave advice about my own money, would I trust it?
Yes. The system computes first, interprets second. It fails gracefully. It prefers "I don't know" over overconfidence. The LLM boundary is explicit and enforced. These are the foundations of trust in financial AI systems.