AI Code Generation Evaluation Engine (Code Arbiter)
Execution-based benchmarking — run the code, classify the failure

The Problem with Most AI Coding Benchmarks
Most AI coding benchmarks ask: "does the output look right?"
That's a weak question. It answers nothing about whether the code actually works, whether it handles edge cases, or what kind of failure the model produces when it gets something wrong.
This project asks a different question: does it pass the tests?
And when it doesn't — why doesn't it?
What I Built
An execution-based benchmarking framework that:
- Sends coding tasks to any AI model (cloud or local)
- Writes the generated code to a temp directory
- Runs it inside an isolated Docker container (network disabled, memory capped)
- Classifies the failure mode when it doesn't pass
- Generates HTML comparison reports with expandable per-task output
The key insight is that running code surfaces information that reviewing code cannot. A syntax error, a logic error, and a temporal reasoning failure all look different in a review — but they produce distinctly different runtime signals. Capturing those signals at scale reveals systematic model weaknesses.
Architecture
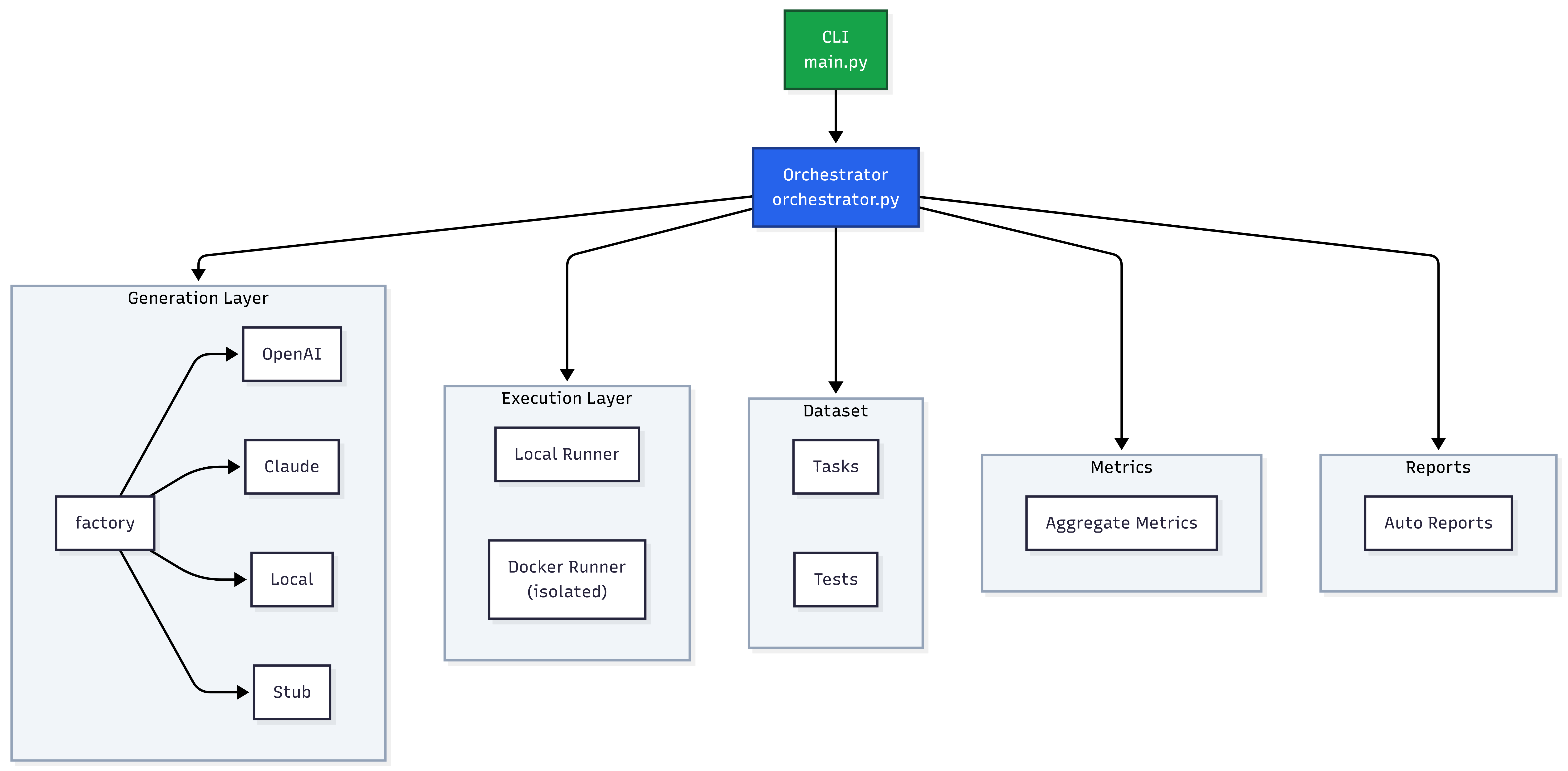
The system is built around a clean separation between task definition, provider integration, execution, and reporting.
Task Layer: 17 non-trivial coding tasks defined as Python test suites — sliding window algorithms, LRU cache with TTL, expression parsers with operator precedence, dependency resolution with cycle detection, token bucket rate limiters, retry-with-backoff implementations. Each task has a clearly specified interface and a pytest suite that validates correctness, edge cases, and performance constraints.
Provider Layer: A pluggable provider interface abstracts over cloud and local models. OpenAI (gpt-4o-mini, gpt-5.4-mini, gpt-5.4) and Anthropic models are supported natively. Local models run via LM Studio's OpenAI-compatible API endpoint — the same provider code works for both, with zero special-casing.
Execution Layer: Each generated code file is written to an isolated temp directory and run inside a fresh Docker container per task. Network access is disabled. Memory is capped. The container is torn down after each run. This prevents any cross-contamination between tasks and stops runaway code from affecting the host.
Failure Classification: When a task fails, the system classifies the failure type:
syntax_error— code doesn't parseruntime_error— code runs but crasheslogic_error— code produces wrong outputtemporal_reasoning_error— code fails on time-window or sequence-dependent tasksedge_case_error— passes core cases, fails on boundary inputsperformance_error— correct but too slow
Reporting Layer: A self-contained HTML report is generated for each benchmark run — dark theme, no external CDN dependencies. Each task is expandable to show the full generated code, test output, and failure classification. A comparison view renders multiple models side-by-side across the same task set.
Key Design Decisions
Execution Over Review
The entire premise of the system is that execution is the ground truth. This eliminates:
- Reviewer subjectivity ("this looks reasonable")
- Prompt-optimization gaming (code that looks clean but doesn't work)
- False positives (working code dismissed as "wrong style")
The test suite is the spec. Pass or fail is binary. Failure classification adds the next layer of signal.
Docker Isolation Per Run
Running generated code on the host is a security risk — and a reliability risk. Without isolation, a failing task could leave temp files, open ports, or modify state that affects the next run.
Docker isolation gives:
- Security: no network, no host filesystem access
- Reproducibility: identical environment for every model, every run
- Clean failure: container exit code maps directly to pass/fail
The overhead is worth it. A benchmark that produces unreliable results due to environmental contamination is worse than a slower benchmark.
Failure Taxonomy Over Binary Pass/Fail
A pass/fail rate tells you which model is better. A failure taxonomy tells you why — which is the actionable signal.
temporal_reasoning_error failures, for example, indicate that a model struggles with tasks that require reasoning about time windows, deadlines, or ordered sequences — not that it can't write Python. That's a completely different failure mode than syntax_error, and it suggests completely different mitigations.
Local Model Parity via LM Studio
Supporting local models through LM Studio's OpenAI-compatible endpoint was a deliberate design choice. It means the same benchmark code, the same tasks, and the same reports apply to both cloud and local models — making cost/performance comparisons rigorous rather than anecdotal.
Results


| Model | Pass Rate | Avg Latency |
|---|---|---|
| gpt-5.4 | 76.5% | 3286ms |
| gpt-5.4-mini | 76.5% | 1537ms |
| Qwen2.5-Coder-7B (local, free) | 70.6% | 1455ms |
| Ministral 3B (local, free) | 64.7% | 988ms |
The headline number is the 6% gap between Qwen2.5-Coder-7B (free, local, 7B parameters) and gpt-5.4 (frontier, API-priced). That's a small gap. The cost difference is $0 vs. ongoing API spend.
But the failure modes are not the same.
The local model fails predominantly on temporal_reasoning_error — tasks involving time windows, rolling calculations, and deadline-aware logic. The frontier model fails occasionally on syntax_error — non-deterministic, usually recoverable with a retry.
That's actionable. For tasks that don't involve temporal reasoning, the local model is competitive. For tasks that do, you need the frontier model. This is the kind of insight a pass/fail rate can't surface.
What I Learned
Failure classification is harder than execution. Determining whether a failure is a logic_error vs. an edge_case_error requires careful task design — the test suite has to be structured to distinguish them. Tasks that only test the happy path can't distinguish logic failures from edge case failures.
Task selection matters more than task count. 17 well-chosen tasks that stress specific capability dimensions (temporal reasoning, data structure invariants, operator precedence, backoff semantics) produce more signal than 100 straightforward "implement fizzbuzz" tasks.
Local models are closer than the benchmarks suggest. The commonly cited capability gap between local 7B models and frontier models is real — but it's concentrated in specific task categories. For general-purpose coding tasks with clear specs, a well-quantized 7B model is competitive with models 100x its size.
Self-contained reports are worth the extra work. Dependency-free HTML reports that work offline, render in any browser, and embed all output mean the benchmark results are portable and archivable. No server, no database, no decay.
Future work
Planned or exploratory directions (same list as the Code Arbiter README — so roadmap lives in one place).
- Agentic coding evaluation — multi-turn sessions, tool use (search, terminal, edits), and end-to-end "agent completes a ticket" runs with execution-based checks at each step.
- Real-world problem solving — tasks with partial specs, legacy codebases, debugging scenarios, and integration-style tests that mirror how software is actually built and maintained.
- Broader task coverage — security-sensitive code, performance constraints, concurrency, and cross-language or polyglot pipelines.
- Richer sandboxes — reproducible dependency graphs, resource limits tuned per task, and optional network or service mocks for API-heavy problems.
- Comparative and longitudinal studies — model/version matrices, regression tracking across releases, and calibration against human baselines where available.
